Assista o Filme Completo Legendado em:
AlphaGo é um programa de computador que joga o jogo de tabuleiro Go. Foi desenvolvido pela DeepMind Technologies, que mais tarde foi adquirida pelo Google. As versões subsequentes do AlphaGo tornaram-se cada vez mais poderosas, incluindo uma versão que competia com o nome de Master.
Depois de se aposentar do jogo competitivo, AlphaGo Master foi sucedido por uma versão ainda mais poderosa conhecida como AlphaGo Zero, que foi completamente autodidata, sem aprender com jogos humanos. AlphaGo Zero foi então generalizado em um programa conhecido como AlphaZero, que jogava jogos adicionais, incluindo Xadrez e Shogi. AlphaZero, por sua vez, foi sucedido por um programa conhecido como MuZero, que aprende sem ser ensinado as regras.

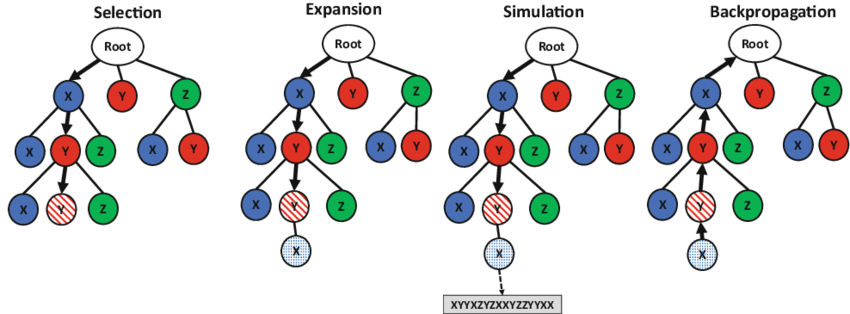
AlphaGo e seus sucessores usam um algoritmo de busca em árvore Monte Carlo para encontrar seus movimentos com base no conhecimento previamente adquirido por aprendizado de máquina, especificamente por uma rede neural artificial (um método de aprendizado profundo) por meio de treinamento extensivo, tanto do jogo humano quanto do computador. Uma rede neural é treinada para identificar os melhores movimentos e as porcentagens de vitória desses movimentos. Essa rede neural melhora a força da busca em árvore, resultando em uma seleção de movimento mais forte na próxima iteração.
Em outubro de 2015, em uma partida contra Fan Hui, o AlphaGo original tornou-se o primeiro programa de computador Go a derrotar um jogador profissional de Go humano, sem handicaps em um tabuleiro 19×19 de tamanho normal. Em março de 2016, ele derrotou Lee Sedol em uma partida de cinco jogos, a primeira vez em que um programa de computador Go derrotou um profissional de 9 dan sem handicap.
Embora tenha perdido para Lee Sedol no quarto game, Lee renunciou no jogo final, dando um placar final de 4 jogos a 1 a favor do AlphaGo. Em reconhecimento à vitória, AlphaGo foi premiado com um 9-dan honorário da Associação de Baduk da Coreia. A preparação e o desafio com Lee Sedol foram documentados em um documentário também intitulado AlphaGo, dirigido por Greg Kohs. A vitória do AlphaGo foi escolhida pela revista científica Science como uma das vice-campeãs do Breakthrough of the Year em 22 de dezembro de 2016.
No Future of Go Summit 2017, a versão Master do AlphaGo derrotou Ke Jie, o jogador número um do mundo na época, em uma partida de três jogos, após o qual o AlphaGo foi premiado com um 9-dan profissional pela Associação Weiqi Chinesa.

Após a partida entre AlphaGo e Ke Jie, a DeepMind aposentou AlphaGo, enquanto continuava a pesquisa de IA em outras áreas.[12] O autodidata AlphaGo Zero alcançou uma vitória de 100-0 contra a versão competitiva inicial de AlphaGo, e seu sucessor AlphaZero é atualmente considerado o melhor jogador do mundo de Go, bem como possivelmente de xadrez.[13][14]
História
O jogo Go é considerado muito mais difícil para os computadores vencerem do que outros jogos, como o xadrez, porque seu fator de ramificação muito maior torna proibitivamente difícil o uso de métodos tradicionais de IA, como poda alfa-beta, travessia de árvore e pesquisa heurística.
Quase duas décadas depois que o computador da IBM Deep Blue derrotou o campeão mundial de xadrez Garry Kasparov na partida de 1997, os programas Go mais fortes usando técnicas de inteligência artificial atingiram apenas o nível amador de 5 dan e ainda não podiam vencer um jogador profissional de Go sem um handicap. Em 2012, o programa de software Zen, rodando em um cluster de quatro PCs, venceu Masaki Takemiya (9p) duas vezes em handicaps de cinco e quatro pedras. Em 2013, Crazy Stone venceu Yoshio Ishida (9p) em uma desvantagem de quatro pedras.
De acordo com David Silver, da DeepMind, o projeto de pesquisa AlphaGo foi formado por volta de 2014 para testar o quão bem uma rede neural usando aprendizado profundo pode competir no jogo Go. AlphaGo representa uma melhoria significativa em relação aos programas Go anteriores. Em 500 jogos contra outros programas Go disponíveis, incluindo Crazy Stone e Zen, AlphaGo rodando em um único computador venceu todos exceto um. Em um confronto semelhante, AlphaGo rodando em vários computadores venceu todos os 500 jogos disputados contra outros programas Go, e 77% dos jogos jogados contra AlphaGo rodando em um único computador. A versão distribuída em outubro de 2015 usava 1.202 CPUs e 176 GPUs.
Jogo contra Fan Hui
Em outubro de 2015, a versão distribuída de AlphaGo derrotou o campeão europeu de Go Fan Hui, um profissional de 2 dan (de 9 dan possíveis), de cinco a zero. Esta foi a primeira vez que um programa de computador Go derrotou um jogador humano profissional em uma placa de tamanho normal sem deficiência. O anúncio da notícia foi adiado até 27 de janeiro de 2016 para coincidir com a publicação de um artigo na revista Nature descrevendo os algoritmos usados.

Jogo contra Lee Sedol
O AlphaGo enfrentou o jogador profissional de Go sul-coreano Lee Sedol, classificado com 9-dan, um dos melhores jogadores de Go, com cinco jogos ocorrendo no Four Seasons Hotel em Seul, Coreia do Sul em 9, 10, 12, 13 e 15 de março de 2016, que foram transmitidos por vídeo ao vivo. Dos cinco jogos, AlphaGo venceu quatro e Lee venceu o quarto jogo, o que o tornou o único jogador humano que venceu AlphaGo em todos os seus 74 jogos oficiais. AlphaGo rodou na computação em nuvem do Google com seus servidores localizados nos Estados Unidos. A partida usou as regras chinesas com um komi de 7,5 pontos, e cada lado teve duas horas de tempo para pensar mais três períodos de byoyomi de 60 segundos. A versão de AlphaGo jogando contra Lee usou uma quantidade semelhante de poder de computação que foi usado na partida de Fan Hui. The Economist relatou que ele usou 1.920 CPUs e 280 GPUs. No momento do jogo, Lee Sedol tinha o segundo maior número de vitórias em campeonatos internacionais Go no mundo, depois do sul-coreano Lee Changho, que manteve o título mundial por 16 anos. Como não existe um único método oficial de classificação no Go internacional, as classificações podem variar entre as fontes. Embora às vezes fosse o melhor classificado, algumas fontes classificaram Lee Sedol como o quarto melhor jogador do mundo na época.

O prêmio da partida foi de US$ 1 milhão. Visto que AlphaGo venceu quatro de cinco e, portanto, a série, o prêmio será doado a instituições de caridade, incluindo a UNICEF. Lee Sedol recebeu $150.000 por participar de todos os cinco jogos e $20.000 adicionais por sua vitória no Jogo 4.
Algoritmo
A partir de 2016, o algoritmo do AlphaGo usa uma combinação de técnicas de aprendizado de máquina e de busca em árvore, combinadas com um treinamento extensivo, tanto de jogo humano quanto de computador. Ele usa a pesquisa em árvore Monte Carlo, guiada por uma “rede de valor” e uma “rede de políticas”, ambas implementadas usando tecnologia de aprendizagem profunda. Uma quantidade limitada de pré-processamento de detecção de recurso específico do jogo (por exemplo, para destacar se um movimento corresponde a um padrão nakade) é aplicada à entrada antes de ser enviada para as redes neurais.
Estilo de jogo
Toby Manning, o árbitro da partida para AlphaGo vs. Fan Hui descreveu o estilo de jogo do programa como “conservador”. O estilo de jogo do AlphaGo favorece fortemente uma maior probabilidade de ganhar por menos pontos em relação à menor probabilidade de ganhar por mais pontos. Sua estratégia de maximizar sua probabilidade de vitória é diferente da que os jogadores humanos tendem a fazer, que é maximizar os ganhos territoriais, e explica alguns de seus movimentos estranhos.
Respostas à vitória de 2016
Comunidade de IA
A vitória da AlphaGo em março de 2016 foi um marco importante na pesquisa de inteligência artificial. O Go já havia sido considerado um problema difícil no aprendizado de máquina, que deveria estar fora do alcance da tecnologia da época. A maioria dos especialistas achava que um programa Go tão poderoso quanto AlphaGo estava a pelo menos cinco anos de distância. Alguns especialistas pensaram que levaria pelo menos mais uma década antes que os computadores derrotassem os campeões de Go. A maioria dos observadores no início das partidas de 2016 esperava que Lee derrotasse o AlphaGo.
Comunidade Go
Go é um jogo popular na China, Japão e Coreia, e as partidas de 2016 foram assistidas por talvez cem milhões de pessoas em todo o mundo. Muitos dos melhores jogadores de Go caracterizaram as jogadas pouco ortodoxas de AlphaGo como movimentos aparentemente questionáveis que inicialmente confundiram os espectadores, mas faziam sentido em retrospectiva: “Todos, exceto os melhores jogadores de Go, criam seu estilo imitando os melhores jogadores. AlphaGo parece ter movimentos totalmente originais que ele mesmo cria.”
Sistemas semelhantes
O Facebook também está trabalhando em seu próprio sistema de Go, Darkforest, também baseado na combinação de aprendizado de máquina e pesquisa de árvore Monte Carlo. Embora um jogador forte contra outros programas de computador Go, no início de 2016, ainda não havia derrotado um jogador profissional humano. Darkforest perdeu para CrazyStone e Zen e estima-se que tenha capacidade semelhante à deles.
Um artigo de 2018 na Nature citou a abordagem do AlphaGo como a base para um novo meio de calcular moléculas de potenciais medicamentos farmacêuticos.
Fontes de pesquisa:
Wikipedia | AlphaGoMovie.Com | Imagens da Internet